주제
회원 정보 관리 API 생성
- 회원 목록 조회
- 회원 조회
- 회원 등록
- 회원 수정
- 회원 삭제
API URI 설계
- 회원 목록 조회 / read-member-list
- 회원 조회 / read-member-by-id
- 회원 등록 / create-member
- 회원 수정 / update-member
- 회원 삭제 / delete-member
이렇게 설계하는 것은 좋은 URI 설계인가?
URI 설계를 할 때 가장 중요한 것은 리로스 식별 입니다.
API URI 고민
- 리소스의 의미는 뭘까?
- 회원 등록/수정/조회 하는게 리소스가 아니다.
- 회원이라는 개념 자체가 바로 리소스이다.
- 리소스를 어떻게 식별하는게 좋을까?
- 회원을 등록, 수정, 조회하는 것을 모두 배제
- 회원이라는 리소스만 식별하면 됨 => 회원 리소스를 URI 에 매핑
리소스와 행위를 분리
가장 중요한 것은 리소스를 식별하는 것
- URI 는 리소스만 식별
- 리소스와 해당 리소스를 대상으로 하는 행위를 분리 ( 리소스 : 회원 / 행위 : 조회,등록,삭제,수정 )
- 리소스는 명사, 행위는 동사 ( 미네랄을 캐라 )
- 행위 ( 메서드 ) 는 어떻게 구분? ( HTTP 메서드 - GET,POST )
HTTP 메서드
클라이언트가 서버에 무언가를 요청을 할 때 기대하는 행동입니다.
[ 주요 메서드 ]
- GET : 리소스 조회
- POST : 요청 데이터 처리, 주로 등록에 사용
- PUT : 리소스를 대체, 해당 리소스가 없으면 생성
- PATCH : 리소스 부분 변경
- DELETE : 리소스 삭제
[ 기타 메서드 ]
- HEAD : GET 과 동일하지만 메시지 부분을 제외하고, 상태 줄과 헤더만 반환
- OPTIONS : 대상 리소스에 대한 통신 가능 옵션(메서드) 를 설명 ( 주로 CORS 에서 사용 )
- CONNECT : 대상 자원으로 식별되는 서버에 대한 터널을 설정
- TRACE : 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행
GET
- 리소스 조회
- 서버에 전달하고 싶은 데이터는 query 를 통해서 전달
- 메시지 바디를 사용해서 데이터 전달 가능하지만, 지원하지 않는 곳이 많아서 권장하지 않음


[ 과정 ]
1. 클라이언트가 GET 메서드로 리소스 요청
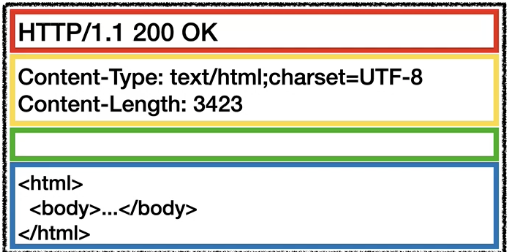
2. 서버는 데이터를 JSON 형태로 응답데이터를 전송해줌
POST
- 요청 데이터 처리
- 메시지 바디를 통해 서버로 요청 데이터 전달
- 서버는 요청 데이터를 처리 -> 메시지 바디를 통해 들어온 데이터를 처리하는 모든 기능 수행
- 주로 전달된 데이터로 신규 리소스 등록, 프로세스 처리에 사용
[ 부가 설명 ]

서버한테 위와 같이 데이터를 줄 것이라고 알려주고,
데이터를 처리해달라고 클라이언트에서 서버로 요청을 하는 것
즉, 핵심은 [ 메시지 바디를 통해 서버로 요청 데이터를 전달 ] 하는 것입니다.
그러면 서버는 이 요청데이터를 받아서 처리하는데, 보통 메시지 바디를 통해 들어온 데이터를 처리하는 모든 기능을
다 수행합니다.



* 신규 등록시, 리소스 등록3 에서 Location 에 자원의 신규 생성된 URI 경로를 적어줍니다.
POST
요청 데이터를 어떻게 처리한다는 뜻일까?
- 스펙 : POST 메서드는 대상 리소스가 리소스의 고유 한 의미 체계에 따라 요청에 포함 된 표현을 처리하도록 요청합니다.
- 예시
- HTML 양식에 입력 된 필드와 같은 데이터 블록을 데이터 처리 프로세스에 제공
ex. HTML 폼에 입력한 정보로 회원가입,주문 등에서 사용
- 게시판, 뉴스, 그룹, 메일링, 리스트, 블로그 또는 유사한 기사 그룹에 메시지 게시
ex. 게시판 글쓰기, 댓글 달기
- 서버가 아직 식별하지 않은 새 리소스 생성
ex. 신규 주문 생성
- 기존 자원에 데이터 추가
ex. 한 문서 끝에 내용 추가하기
- 정리 : 이 리소스 URI 에 POST 요청이 오면 요청 데이터를 어떻게 처리할지 리소스마다 따로 정해야함 ( 정해진게 없음 )
POST 정리
- 새 리소스 생성 ( 등록 ) - 서버가 아직 식별하지 않은 새 리소스 생성
- 요청 데이터 처리
- 단순히 데이터를 생성/변경하는 것을 넘어서 프로세스를 처리하는 경우
ex. 주문의 결제완료 -> 배달시작 -> 배달 완료처럼 단순히 값 변경을 넘어 프로세스의 상태가 변경되는 경우
( 배달 시작을 누르게되면 그 후에 굉장히 큰 프로세스가 실행됨 )
- POST 의 결과로 새로운 리소스가 생성되지 않을 수 있음
ex. POST /orders/{ordered}/start-delivery ( 컨트롤 URI )
- 다른 메서드로 처리하기 애매한 경우 ( JSON 으로 조회 데이터 넘겨야하는데, GET 사용 어려운 경우 )
PUT
- 리소스 수정이 아니라 리소스를 완전히 갈아치움
- 리소스가 있으면 대체 ( 쉽게 말해 덮어 쓰기 )
- 리소스가 없으면 생성
- 클라이언트가 리소스 위치를 알고 URI 지정 ( POST 와의 차이점 )
- 즉, 클라이언트가 리소스 위치를 알고 있어야함.

위의 예제에서 만약 member/100 리소스가 없으면, 신규로 생성이 됩니다.
그런데 만약 있으면 [ 기존것은 없어지고 새로 들어감 ]
[ age 만 50으로 수정 ] 을 하고 싶어도 username 이 없어지고 age 50이 들어와버립니다.
그래서 이러한 수정을 위해서 PATCH 를 사용합니다.
PATCH
- 리소스 부분 변경
- PATCH 를 못쓰는 버젼이 있어서 그런 경우 POST 를 사용해야함
DELETE
리소스 제거

'HTTP' 카테고리의 다른 글
| RestAPI 활용하기 (0) | 2022.08.22 |
|---|---|
| Message States Server (0) | 2022.08.19 |
| HTTP 메서드와 속성 (0) | 2022.08.18 |
| HTTP - 짧게 정리 (0) | 2022.08.13 |
| HTTP (0) | 2022.08.03 |