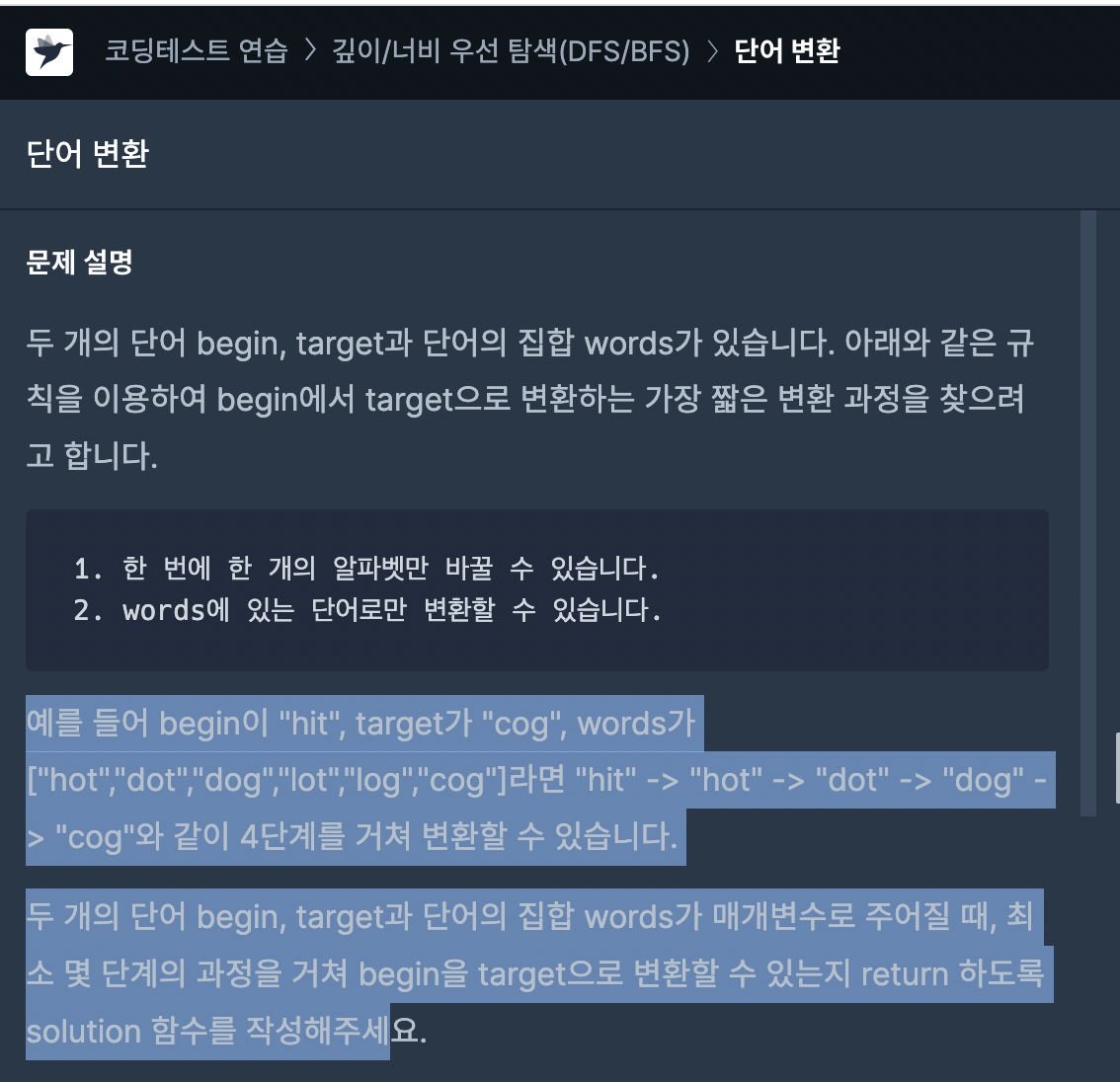
/**
* - 문제
* 방문하는 공항 경로를 배열에 담아 출력
* - 조건
* 1) 주어진 항공권을 모두 이용해 여행경로를 구성
* 2) 항상 ICN 공항에서 출발
* 3) 만약 출발 경로가 같을 경우 정렬 필요
**/
[ 제가 작성한 코드 ]
import java.util.Arrays;
import java.util.Comparator;
import java.util.Stack;
public class TripCourse {
/**
* - 문제
* 방문하는 공항 경로를 배열에 담아 출력
* - 조건
* 1) 주어진 항공권을 모두 이용해 여행경로를 구성
* 2) 항상 ICN 공항에서 출발
**/
private static boolean[] visit;
private static Stack<String> stack = new Stack<>();
private static String[] answer;
private static int cnt = 0;
public static void main(String[] args) {
String[][] tickets = {
{"ICN", "SFO"}, {"ICN", "ATL"}, {"SFO", "ATL"}
,{"ATL","ICN"},{"ATL","SFO"}};
String[][] tickets2 = {
{"ICN", "JFK"}, {"HND", "IAD"}, {"JFK", "HND"}
};
String res = Arrays.toString(solution(tickets));
System.out.println(res);
}
public static String[] solution(String[][] tickets) {
answer = new String[tickets.length + 1];
visit = new boolean[tickets.length];
answer[cnt++] = tickets[0][0];
for (int i = 1; i < tickets.length; i++) {
String prev = tickets[i-1][0];
if (tickets[i][0].equals(prev)) {
Arrays.sort(tickets, new Comparator<String[]>() {
@Override
public int compare(String[] o1, String[] o2) {
return o1[1].compareTo(o2[1]);
}
});
break;
}
}
dfs(tickets,tickets[0][1],0);
return answer;
}
public static void dfs(String[][] tickets, String start, int check) {
stack.push(start);
visit[check] = true;
while (!stack.isEmpty()) {
String nodeString = stack.pop(); // 방문 노드
answer[cnt++] = start;
for (int i = 0; i < tickets.length; i++) {
if (tickets[i][0].equals(nodeString)) {
if(!visit[i]){
dfs(tickets, tickets[i][1], i);
}
}
}
}
}
}
[ 코드 채점 결과 ]

[ 다른 사람 코드 리뷰 ]
1) 모든 경우의 수를 구한 다음 Collections.sort() 를 통해 정렬하기 위해 리스트 선언
2) 첫 출발은 항상 "ICN" 이기 때문에 DFS 시작을 "ICN"으로 해주고, route 시작도 "ICN" 으로 시작해준다.
3) DFS 함수에서 모든 티켓을 다 썼을 때, allRoute에 구한 경로를 add() 해준다.
4) 연결되어 있는 공항으로 꼬리물기를 하며 티켓의 시작 공항이 start 와 같고 방문하지 않은경우
dfs() 의 start 자리에 ticket[i][1] 을 넣고 재탐색해준다.
5) 이때 visited[i] = false 로 바꿔 주는 이유는 모든 경로를 탐색하기 위함이다.
6) 모든 경우의 수를 allRoute에 넣은 후 Collections.sort() 로 정렬하고
첫번째 문자를 가져오게 되면 알파벳 순으로 가장 빠른 경로를 구할 수 있다.
이때, split() 을 통해 문제에서 원하는 출력으로 바꿔준다.
import java.util.*;
public class TripCourse {
/**
* - 문제
* 방문하는 공항 경로를 배열에 담아 출력
* - 조건
* 1) 주어진 항공권을 모두 이용해 여행경로를 구성
* 2) 항상 ICN 공항에서 출발
**/
private static boolean[] visit;
private static ArrayList<String> allRoute;
public static void main(String[] args) {
String[][] tickets = {
{"ICN", "SFO"}, {"ICN", "ATL"}, {"SFO", "ATL"}
,{"ATL","ICN"},{"ATL","SFO"}};
String[][] tickets2 = {
{"ICN", "JFK"}, {"HND", "IAD"}, {"JFK", "HND"}
};
String res = Arrays.toString(solution(tickets));
System.out.println(res);
}
public static String[] solution(String[][] tickets) {
String[] answer = {};
int cnt = 0;
visit = new boolean[tickets.length];
allRoute = new ArrayList<>();
dfs("ICN", "ICN", tickets, cnt);
Collections.sort(allRoute);
answer = allRoute.get(0).split(" ");
return answer;
}
public static void dfs(String start, String route, String[][] tickets, int cnt) {
if (cnt == tickets.length) {
allRoute.add(route);
return;
}
for (int i = 0; i < tickets.length; i++) {
if (start.equals(tickets[i][0]) && !visit[i]) {
visit[i] = true;
dfs(tickets[i][1], route + " " + tickets[i][1], tickets, cnt+1);
visit[i] = false;
}
}
}
}