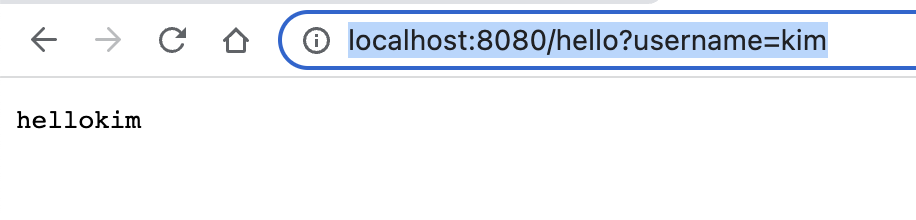
- 문제 : n의 다음 튼 숫자를 정의해라
1) n 보다 큰 자연수
2) n 을 2진수로 변환했을 때 1의 갯수
3) 조건 1,2를 만족하는 수 중 가장 작은 수
- 과정 :
1) 2진수로 변환 후 갯수 구한다. (k)
2) n을 증가시키며 k를 비교한다.
위 과정을 소스코드로 구현하면 다음과 같습니다.
[ 소스 코드 ]
public class 다음큰숫자 {
/**
- 문제 : n의 다음 튼 숫자를 정의해라
1) n 보다 큰 자연수
2) n 을 2진수로 변환했을 때 1의 갯수
3) 조건 1,2를 만족하는 수 중 가장 작은 수
- 과정 :
1) 2진수로 변환 후 갯수 구한다. (k)
2) n을 증가시키며 k를 비교한다.
**/
public static void main(String[] args) {
System.out.println(solution(78));
}
public static int solution(int n) {
int answer = 0;
String s = Integer.toBinaryString(n);
int nLen = 0;
for (int i = 0; i < s.length(); i++) {
if('1' == s.charAt(i)) nLen++;
}
int oneLen = 0;
while(n <= 1000000){
n += 1;
String s2 = Integer.toBinaryString(n);
for (int i = 0; i < s2.length(); i++)
if('1' == s2.charAt(i)) oneLen++;
if(nLen == oneLen) break;
oneLen = 0;
}
answer = n;
return answer;
}
}
위 문제를 단순히 나머지3으로 구하려고 하면 문제가 풀리지 않는다는 것을 알 수 있습니다.
- 문제 :
124 나라에서는 10진법이 아닌 자신만의 규칙으로 수를 표현
1) 자연수만 존재
2) 모든 수를 표현할 때, 1/2/4 만 사용
ex. 3 = 4, 4 = 11, 5 = 12, 6 = 14 ...
- 출력:
n 이 입력됬을 때, 124 나라에서 사용하는 숫자로 바꾼 값을 반환해라
- 공식:
1) 입력 n이 들어온다.
2) n의 나머지 3을 구해 k값을 뽑는다.
3) k 값은 [ 4, 1, 2 ] 배열의 인덱스 값을 의미한다.
4) n을 3으로 나눠준다.
5) 이때, 나머지가 0이면 나눠떨어지는 것이므로 n을 3으로 나눈 후 -1을 해준다.
위의 공식을 코드로 구현하면 다음과 같습니다.
[ 소스 코드 ]
public class 나라의숫자 {
/**
- 문제 :
124 나라에서는 10진법이 아닌 자신만의 규칙으로 수를 표현
1) 자연수만 존재
2) 모든 수를 표현할 때, 1/2/4 만 사용
ex. 3 = 4, 4 = 11, 5 = 12, 6 = 14 ...
- 출력:
n 이 입력됬을 때, 124 나라에서 사용하는 숫자로 바꾼 값을 반환해라
- 공식:
1) 입력 n이 들어온다.
2) n의 나머지 3을 구해 k값을 뽑는다.
3) k 값은 [ 4, 1, 2 ] 배열의 인덱스 값을 의미한다.
4) n을 3으로 나눠준다.
5) 이때, 나머지가 0이면 나눠떨어지는 것이므로 n을 3으로 나눈 후 -1을 해준다.
**/
public static void main(String[] args) {
System.out.println(solution(5));
}
public static String solution(int n) {
String answer = "";
String[] number = {"4", "1", "2"};
while (n > 0) {
int reminder = n % 3;
n /= 3;
if(reminder == 0) n--;
answer = number[reminder] + answer;
}
return answer;
}
}
import java.util.ArrayList;
import java.util.List;
import java.util.Locale;
public class 캐시 {
/**
- 설명 :
1. 테스팅 업무는 어피치
2. 제이지가 작성한 데이터베이스에서 게시물 불러오는 부분의 실행시간이 오래걸림
3. 어피치는 제이지에게 해당 로직 개선하라고 지시
4. 제이지는 DB 캐시를 적용하여 성능 개선을 시도하지만 효율적인 캐시 크기를 몰라 난감
- 입력 형식 :
캐시 크기 ( cacheSize ), 도시 이름 배열 ( cities )
- 입력 조건 :
공백, 숫자, 특수문자 등이 없는 영문자
대소문자 구분안함
최대 20자
- 조건 :
캐시 교체 알고리즘 > LRU 사용
cache hit일 경우 실행 시간은 1
cache miss일 경우 실행 시간은 5
- 용어 설명 :
1) 캐시 히트 = 캐시 메모리에 찾는 데이터가 존재했을 때
2) 캐시 미스 = 캐시 메모리에 찾는 데이터가 존재하지 않았을 때
**/
public static void main(String[] args) {
int cache = 3;
String[] cities = {
"Jeju", "Pangyo", "Seoul", "NewYork", "LA", "Jeju", "Pangyo", "Seoul", "NewYork", "LA"
};
System.out.println(solution(cache, cities));
}
public static int solution(int cacheSize, String[] cities) {
for (int i = 0; i < cities.length; i++) {
cities[i] = cities[i].toLowerCase(Locale.ROOT);
}
int answer = LRU(cacheSize, cities);
return answer;
}
public static int LRU(int s, String[] cities){
List<String> temp = new ArrayList<>();
int excuteTime = 0;
int cnt = 0;
boolean check = false;
while (cnt < cities.length) {
for (int i = 0; i < temp.size(); i++) {
if (temp.get(i).equals(cities[cnt])) {
excuteTime += 1;
temp.add(0, cities[cnt]);
check = true;
break;
}
}
if (!check){
temp.add(0, cities[cnt]);
excuteTime += 5;
}
if (temp.size() > s) {
temp.remove(temp.size() - 1);
}
cnt++;
check = false;
}
return excuteTime;
}
}
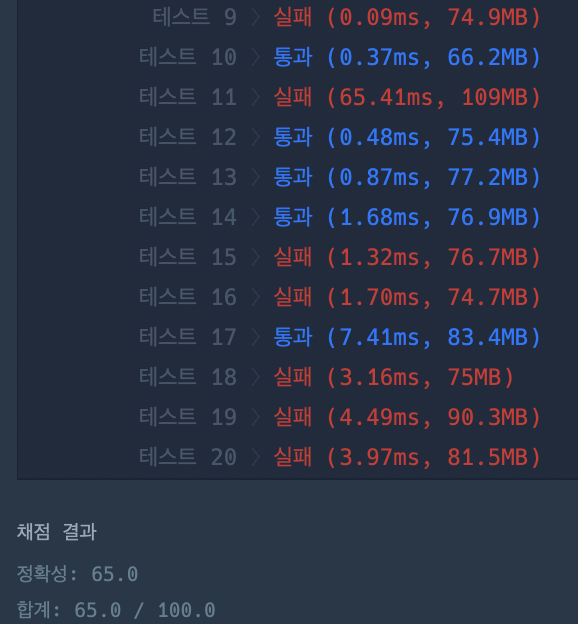
테스트 9번부터 실패가 발생함을 볼 수 있습니다.
그 이유는 기존의 캐시에 같은 값이 있는 경우 기존의 값을 삭제해주고 최신화를 해줘야하는데 이 부분을 놓쳤기 때문입니다.
( 추가된 부분 )
[ 정답 소스 코드 ]
import java.util.ArrayList;
import java.util.List;
import java.util.Locale;
public class 캐시 {
/**
- 설명 :
1. 테스팅 업무는 어피치
2. 제이지가 작성한 데이터베이스에서 게시물 불러오는 부분의 실행시간이 오래걸림
3. 어피치는 제이지에게 해당 로직 개선하라고 지시
4. 제이지는 DB 캐시를 적용하여 성능 개선을 시도하지만 효율적인 캐시 크기를 몰라 난감
- 입력 형식 :
캐시 크기 ( cacheSize ), 도시 이름 배열 ( cities )
- 입력 조건 :
공백, 숫자, 특수문자 등이 없는 영문자
대소문자 구분안함
최대 20자
- 조건 :
캐시 교체 알고리즘 > LRU 사용
cache hit일 경우 실행 시간은 1
cache miss일 경우 실행 시간은 5
- 용어 설명 :
1) 캐시 히트 = 캐시 메모리에 찾는 데이터가 존재했을 때
2) 캐시 미스 = 캐시 메모리에 찾는 데이터가 존재하지 않았을 때
**/
public static void main(String[] args) {
int cache = 3;
int cache2 = 0;
int cache3 = 2;
String[] cities = {
"Jeju", "Pangyo", "Seoul", "NewYork", "LA", "Jeju", "Pangyo", "Seoul", "NewYork", "LA"
};
String[] cities2 = {
"Jeju", "Pangyo", "Seoul", "NewYork", "LA"
};
String[] cities3 = {
"Jeju", "Pangyo", "NewYork", "newyork"
};
System.out.println(solution(cache3, cities3));
}
public static int solution(int cacheSize, String[] cities) {
for (int i = 0; i < cities.length; i++) {
cities[i] = cities[i].toLowerCase(Locale.ROOT);
}
int answer = LRU(cacheSize, cities);
return answer;
}
public static int LRU(int s, String[] cities){
List<String> temp = new ArrayList<>();
int excuteTime = 0;
int cnt = 0;
boolean check = false;
while (cnt < cities.length) {
for (int i = 0; i < temp.size(); i++) {
if (temp.get(i).equals(cities[cnt])) {
excuteTime += 1;
temp.remove(temp.get(i));
temp.add(0, cities[cnt]);
check = true;
break;
}
}
if (!check){
temp.add(0, cities[cnt]);
excuteTime += 5;
}
if (temp.size() > s) {
temp.remove(temp.size() - 1);
}
cnt++;
check = false;
}
excuteTime += (s - temp.size());
return excuteTime;
}
}
새로운 페이지를 할당하기 위해 현재 할당된 페이지 중 어느 것과 교체할 지를 결정하는 방법
종류 : FIFO, LFU, LRU
1) FIFO : 페이지가 주기억장치에 적재된 시간을 기준으로 교체될 때 페이지를 선정하는 기법
2) LFU : 가장 최근에 사용한 프로그램 중 적은 횟수로 참조하는 페이지 교체
3) LRU : 가장 오랫동안 참조되지 않은 페이지 교체
LRU 알고리즘
[ 예시 ]
Input : 12345
Output : 5413
위의 그림에서 참조 스트링이 입력되고, 이에 따른 주기억 장치의 상태를 보면 됩니다.
- 4초 : 1 이 재참조되어 순서가 변경됩니다.
- 6초 : 캐시사이즈가 가득차서 가장 오랫동안 참조되지 않은 2를 제거 후 저장합니다.
[ 문제 ]
캐시 크기가 주어지고, 캐시가 비어 있는 상태에서 N개의 작업을 CPU가 차례대로 처리한다면 N개의 작업을 처리한 후
캐시 메모리 상태를 가장 최근 사용된 작업부터 차례대로 출력하는 프로그램을 작성하시오.
- 입력
1) 첫 번째 줄에 캐시 크기 (S) 와 작업 개수 (N) 이 입력됨
2) 두 번째 줄에 N 개의 작업 번호가 처리순으로 주어짐 ( 1 ~ 100 )
- 출력
마지막 작업 후 캐시메모리의 상태를 가장 최근 사용된 작업부터 차례로 출력
[ 예시 입력 ]
5 9
1 2 3 2 6 2 3 5 7
[ 과정 ]
1) 1
2) 2 1
3) 3 2 1
4) 2 3 1
5) 6 2 3 1
6) 2 6 3 1
7) 3 2 6 1
8) 5 3 2 6 1
9) 7 5 3 2 6
[ 예시 출력 ]
7 5 3 2 6
[ 소스코드 ]
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class LRU {
public static void main(String[] args) {
Scanner kb = new Scanner(System.in);
int s = kb.nextInt();
int n = kb.nextInt();
List<Integer> arr = new ArrayList<>();
for (int i = 0; i < n; i++) {
arr.add(kb.nextInt());
}
myLRU(s, arr);
}
public static void myLRU(int s, List<Integer> arr) {
List<Integer> temp = new ArrayList<>();
int cnt = 0;
boolean check = false;
while (cnt < arr.size()) {
// 이미 숫자가 있는지 확인
for (int i = 0; i < temp.size(); i++) {
if (temp.get(i) == arr.get(cnt)) {
temp.remove(i);
temp.add(0,arr.get(cnt));
check = true;
break;
}
}
if(!check){
temp.add(0,arr.get(cnt));
}
// 최대 크기를 넘은 경우
if(temp.size() > s){
temp.remove(temp.size() - 1);
}
cnt++;
check = false;
}
for (Integer i : temp) {
System.out.print(i + " ");
}
}
}
두 배열 각각에서 하나의 숫자를 뽑아 두 수를 곱합니다.
이러한 과정에서 배열의 길이만큼 반복하여 두 수를 곱한 값을 누적하여 더합니다.
이때 최종적으로 누적된 값이 최소가 되는게 목표입니다.
조건
각 배열에서 k번째 숫자를 뽑았다면 다음에 k번째 숫자를 다시 뽑을 수 없음
해결 과정
1) 예를 들어, [ 1*2+3*3= 11 ], [ 1*3+3*2 = 9 ] 이와 같이 가장 큰 수에 가장 작은 수를 곱해줘야 합니다.
2) 그래서 두 배열 각각을 오름차순, 내림차순으로 정렬한다.
3) 곱을 누적시킨다.
소스코드
import java.util.*;
public class 최솟값만들기 {
/**
- 문제 설명:
두 배열 각각에서 하나의 숫자를 뽑아 두 수를 곱합니다.
이러한 과정에서 배열의 길이만큼 반복하여 두 수를 곱한 값을 누적하여 더합니다.
이때 최종적으로 누적된 값이 최소가 되는게 목표입니다.
- 조건 :
각 배열에서 k번째 숫자를 뽑았다면 다음에 k번째 숫자를 다시 뽑을 수 없음
- 해결 과정 :
1) 예를 들어, [ 1*2+3*3= 11 ], [ 1*3+3*2 = 9 ] 이와 같이 가장 큰 수에 가장 작은 수를 곱해줘야 합니다.
2) 그래서 두 배열 각각을 오름차순, 내림차순으로 정렬한다.
3) 곱을 누적시킨다.
**/
public static void main(String[] args) {
int[] A = {1,2};
int[] B = {3,4};
System.out.println(solution(A,B));
}
public static int solution(int []A, int []B)
{
int answer = 0;
Integer[] Bin = new Integer[B.length];
Arrays.sort(A);
for (int i = 0; i < B.length; i++) {
Bin[i] =Integer.valueOf(B[i]);
}
Arrays.sort(Bin,Collections.reverseOrder());
for (int i = 0; i < B.length; i++) {
answer += A[i] * Bin[i];
}
return answer;
}
}
: 1 ~ n까지 번호가 붙어 있는 n명의 사람이 영어 끝말잇기 진행
1) 1번부터 번호순으로 차례대로 단어 말함
2) 마지막 사람이 단어를 말한 다음 다시 1번부터 시작
3) 앞 사람이 말한 단어의 마지막 문자로 시작하는 단어 말함
4) 이전에 등장했던 단어는 사용 못함
5) 한 글자 단어는 사용 금지
1) 경우에 대한 조건문 작성
2) 번호 : i+1 % n
3) 몇 번째 차례 : i / n 보다 큰 첫번째 정수
소스코드
import java.util.ArrayList;
import java.util.Arrays;
public class 영어끝말잇기 {
/**
- 문제 설명: 1 ~ n까지 번호가 붙어 있는 n명의 사람이 영어 끝말잇기 진행
1) 1번부터 번호순으로 차례대로 단어 말함
2) 마지막 사람이 단어를 말한 다음 다시 1번부터 시작
3) 앞 사람이 말한 단어의 마지막 문자로 시작하는 단어 말함
4) 이전에 등장했던 단어는 사용 못함
5) 한 글자 단어는 사용 금지
- 출력 :
가장 먼저 탈락하는 사람의 번호, 그 사람이 몇 번째에 탈락하는지를 구함
- 조건 :
1) 단어길이 - 2~50
2) 배열길이 - n ~ 100이하
3) 소문자
4) 탈락자가 생기지 않는다면 0,0 반환
- 해결 방법 :
1) 경우에 대한 조건문 작성
2) 번호 : i+1 % n
3) 몇 번째 차례 : i / n 보다 큰 첫번째 정수
**/
public static void main(String[] args) {
String[] input = {"hello", "one", "even", "never", "now", "world", "draw"};
String result = Arrays.toString(solution(2, input));
System.out.println(result);
}
public static int[] solution(int n, String[] words) {
ArrayList<String> arr = new ArrayList<>();
int[] answer = new int[2];
String prev = words[0];
arr.add(words[0]);
for(int i=1; i<words.length; i++){
char CanFirstLetter = prev.charAt(prev.length()-1);
if(words[i].length() == 1){
System.out.println("issue oneLetter: "+i);
answer[0] = (i % n) + 1;
answer[1] = (i/n)+1;
return answer;
}
if(CanFirstLetter != words[i].charAt(0)){
System.out.println("issue not: "+i);
answer[0] = (i % n) + 1;
answer[1] = (i/n)+1;
return answer;
}
if (arr.contains(words[i])) {
System.out.println("issue contain: "+i);
answer[0] = (i % n) + 1;
answer[1] = (i/n)+1;
return answer;
}
prev = words[i];
arr.add(words[i]);
}
answer[0] = 0;
answer[1] = 0;
return answer;
}
}
> 입력 : 알파벳 소문자로 이뤄진 문자열
> 과정 :
1) 문자열에서 같은 알파벳 두 개가 붙어있는 짝을 찾음
2) 과정을 반복해서 문자열 모두 제거하면 짝지어 제거하기가 종료
3) 성공적인 수행은 1, 아니면 0 을 리턴
해결 방식
1) Stack 활용
[ 반복문 ]
2) 문자열을 순회하며 스택에서 peek()한 요소와 현재 순회중인 문자가 같으면 pop
3) 아니면 push()
4) 만약 스택이 비어있으면 push
[ 출력 ]
5) 만약 스택이 비어 있으면 1 출력
6) 아니면 0 출력
소스코드
import java.util.Stack;
public class 짝지어제거하기 {
/**
- 문제 설명:
> 입력 : 알파벳 소문자로 이뤄진 문자열
> 과정 :
1) 문자열에서 같은 알파벳 두 개가 붙어있는 짝을 찾음
2) 과정을 반복해서 문자열 모두 제거하면 짝지어 제거하기가 종료
3) 성공적인 수행은 1, 아니면 0 을 리턴
- 해결 방식:
1) Stack 활용
[ 반복문 ]
2) 문자열을 순회하며 스택에서 peek()한 요소와 현재 순회중인 문자가 같으면 pop
3) 아니면 push()
4) 만약 스택이 비어있으면 push
[ 출력 ]
5) 만약 스택이 비어 있으면 1 출력
6) 아니면 0 출력
**/
public static void main(String[] args) {
System.out.println(solution("baabaa"));
}
public static int solution(String s)
{
int answer = -1;
Stack<Character> stack = new Stack<>();
for (int i = 0; i < s.length(); i++) {
if(stack.isEmpty()){
stack.push(s.charAt(i));
}
else if (stack.peek() == s.charAt(i)) {
stack.pop();
} else {
stack.push(s.charAt(i));
}
}
if(stack.isEmpty()) answer = 1;
else answer = 0;
return answer;
}
}
public class 피보나치수열 {
/*
- 문제 : 숫자 n이 주어지고, 그 수를 1234567 로 나눈 나머지를 리턴하는 함수를 작성해라
* */
public static void main(String[] args) {
System.out.println(solution(3));
}
public static int solution(int n) {
int[] answer = new int[n + 1];
for (int i = 0; i <= n; i++) {
if(i==0) answer[i] = 0;
else if(i==1) answer[i] = 1;
else{
int sum = answer[i-2] + answer[i-1];
answer[i] = sum % 1234567;
}
}
return answer[n];
}
}
- 유클리드 호제법 알고리즘으로 최대 공약수를 구한다.
- 첫 번째 원소 * 두 번째 원소 / gcd 의 계산을 해서 배열들의 최소 공배수를 구함
[ 소스 코드 ]
public class n개의최소공배수 {
/*
- 배열의 공배수가 되는 가장 작은 숫자를 구해라
[ 해결과정 ]
- 유클리드 호제법 알고리즘으로 최소 공배수/최대 공약수를 구한다.
- 여기서 구한 최소 공배수를 다음 배열에 반복
*/
public static void main(String[] args) {
int[] arr = {2, 6, 8, 14};
System.out.println(solution(arr));
}
public static int solution(int[] arr) {
int answer = arr[0];
for (int i = 1; i < arr.length; i++) {
int gcd = gcd(answer, arr[i]); // 최대 공약수
answer = answer * arr[i] / gcd; // 최소 공배수
}
return answer;
}
public static int gcd(int a,int b){
int max = Math.max(a, b);
int min = Math.min(a, b);
while(max % min != 0){
int r = max % min;
max = min;
min = r;
}
return min;
}
}
입력에는 두 개의 식이 순서대로 입력된다.첫 번째 식은 첫 줄에는 항의 개수n (1<=n<=20)이 들어온다. 다음 줄 부터는 최고차항 순서로 (계수,차수)가 들어오며 공백으로 구분된다.두 번째 식도 같은 방법으로 입력된다.
[ Output ]
먼저, 두 개의 식을“(항의 개수) =다항식”의 형식으로 각 줄에 출력한다. 이때 Sample Output에 맞추어 공백을 구분하는데 유의한다. 각 계수는 소수점 첫째자리 까지 출력하고 계수가 0인 항은 출력하지 않는다 (Sample Output 참고). 그리고 마지막줄에는 두 개의 다항식을 더하여 하나의 다항식으로 출력한다.
#include <cstdio>
#include <iostream>
using namespace std;
#define MAX_DEGREE 80
int degreeArr[MAX_DEGREE]; // degree 입력 배열
class polynomial{
float coef[MAX_DEGREE]; // 계수 입력 배열
int polyNum[MAX_DEGREE]; // 차수 입력 배열
public:
int degree;
polynomial(){
degree = 0;
}
void read(int num){
scanf("%d",°ree);
degreeArr[num] = degree;
for(int i=0; i<degree; i++){
scanf("%f %d",coef+i, polyNum+i);
}
}
void display(int num){
printf("(%d) = ",num);
for(int i=0; i<degree; i++){
if(i == degree-1){
printf("%.1f x^%d", coef[i], polyNum[i]);
}
else printf("%.1f x^%d + ", coef[i], polyNum[i]);
}
printf("\n");
}
void add( polynomial a, polynomial b){
/*
차수가 큰 다항식을 자신으로 복사 후 나머지 계수를 자기 계수 배열에
차수를 맞춰 더한다.
- 해결할 문제
1) degree 순이 아닌 높은 차수 순으로 정렬
- 해결 과정
1) c에 a를 복사한다.
2) b의 차수 배열과 c의 차수 배열을 비교해서 c에 넣어준다.
3) 넣어주는 조건
> c 차수가 b의 차수보다 큰 경우 b의 해당 원소 앞에 넣어준다.
> c 차수 배열의 마지막 원소보다 b의 차수가 작다면 뒤로 배열을 다 넣어준다.
> c 차수와 b차수가 같은 경우 b의 해당 계수을 더해준다.
*/
*this = a; // c = a의 degree 와 polyNum 이 복사됨
int degreeCnt = 0;
for(int i=0; i<b.degree; i++){ // b를 순환
for(int j=0; j<degree; j++){ // c에서 제 자리를 찾기 위해 c를 순환
if(polyNum[j] < b.polyNum[i]){ //b의 차수가 c의 차수보다 큰 경우
int insertPoef = b.polyNum[i];
int insertCoef = b.coef[i];
for(int k=degree; k >= j; k--){
coef[k+1] = coef[k];
polyNum[k+1] = polyNum[k];
}
polyNum[j] = insertPoef;
coef[j] = insertCoef;
degreeCnt++; // degree 증가 카운트를 해놓고 반복문이 끝나면 degree에 더해준다.
j = j+1; // 자릿수가 늘어남에 따라 j도 증가
break;
}
else if(polyNum[j] == b.polyNum[i]){ //b와 c의 차수가 같은 경우
coef[j] += b.coef[i];
break; // 더 해주는게 반복되지 않게 종료시켜줌
}
}
degree += degreeCnt;
degreeCnt = 0;
}
}
bool isZero(){
return degree == 0;
}
void negate(){
for(int i=0; i<degree ;i++) coef[i] = -coef[i];
}
};
int main(){
polynomial a,b,c;
a.read(0);
b.read(1);
c.add(a,b);
int num = c.degree;
a.display(degreeArr[0]);
b.display(degreeArr[1]);
c.display(num);
return 0;
}
- 문제 설명:
길이가 같은 두 개의 큐가 주어짐
> 하나의 큐를 골라 원소를 추출
> 추출된 원소를 다른 큐에 집어 넣는 작업을 수행
> 그 작업을 통해 각 큐의 원소 합을 같게 만듬
> 이때, 필요한 작업의 최소 횟수를 구해라
> 한 번씩 pop,insert 를 하면 작업 수행 1회로 간주
- 주의
> long type 권장
> 큐 길이 : 30만
> 원소 크기 : 10에 9승
[ 해결 방법 ]
* s1 = 배열1의 합 | s2 = 배열2의 합 | sum = 배열1,2의 합/2
* problem1,2 = pop(), insert() 한 횟수
1) 입력 받은 배열을 Queue 에 넣어준다.
2) 두 배열의 합이 만약 홀수이면 -1을 리턴해준다.
3) 합을 나누기 2를 해준다.
4) 반복문을 통해 아래의 내용을 비교해준다. ( 반복문은 problem1,2 가 큐의 길이가 두배가 되면 종료 )
- s1 이 sum 과 같으면 problem1 + problem2 를 리턴해준다.
- s1 이 sum 보다 크면,
s1 에 queue1 에서 peek() 한 값을 빼줌 s2 에는 더해줌 queue2 에 queue1 을 pop() 한 값을 poll() 해줌 problem1 을 하나 증가시킴
- 둘 다 아니면,
s2 에 queue2 에서 peek() 한 값을 빼줌 s1 에 더해줌 queue1 에 queue2를 pop()한 값을 poll() 해줌 problem2 를 하나 증가시팀
[ 소스 코드 ]
import java.util.ArrayDeque;
import java.util.Queue;
public class 큐문제 {
/**
- 문제 설명:
길이가 같은 두 개의 큐가 주어짐
> 하나의 큐를 골라 원소를 추출
> 추출된 원소를 다른 큐에 집어 넣는 작업을 수행
> 그 작업을 통해 각 큐의 원소 합을 같게 만듬
> 이때, 필요한 작업의 최소 횟수를 구해라
> 한 번씩 pop,insert 를 하면 작업 수행 1회로 간주
- 주의
> long type 권장
> 큐 길이 : 30만
> 원소 크기 : 10에 9승
**/
public static void main(String[] args) {
int[] queue1 = {3, 2, 7, 2};
int[] queue2 = {4, 6, 5, 1};
int solution = solution(queue1, queue2);
System.out.println(solution);
}
public static int solution(int[] queue1, int[] queue2) {
Queue<Integer> que1 = new ArrayDeque<>();
Queue<Integer> que2 = new ArrayDeque<>();
long s1 = 0, s2 = 0, sum = 0;
for (int i = 0; i < queue1.length; i++) {
que1.add(queue1[i]);
s1 += queue1[i];
que2.add(queue2[i]);
s2 += queue2[i];
}
sum = s1 + s2;
// 홀수가 될 경우 풀 수 없음
if (sum % 2 == 1) return -1;
sum = sum/2;
int problem1 = 0;
int problem2 = 0;
int limit = queue1.length * 2;
while (problem1 <= limit && problem2 <= limit) {
if(s1 == sum) return problem1 + problem2;
else if(s1 > sum){
s1 -= que1.peek();
s2 += que1.peek();
que2.add(que1.poll());
problem1++;
}
else {
s1 += que2.peek();
s2 -= que2.peek();
que1.add(que2.poll());
problem2++;
}
}
return -1;
}
}
갈색 격자수, 노란색 격자 수 yellow 가 매개변수로 주어질 때,
카펫의 가로/세로 크기를 수너대로 담은 배열을 나타내라
- 단, 중앙에는 노란색, 테두리 1줄은 갈색으로 칠해져 있음
[ 풀이 방법 ]
1) 갈색,노란색 격자 수를 더한 값의 약수를 구한다.
2) 그 약수 중에 정답이 있다.
3) (가로-2) * (세로-2) = 노란색의 개수이다.
* 조건 : 가로 길이 >= 세로 길이
[ 처음 시도 한 소스 코드 ]
import java.util.ArrayList;
public class 카펫 {
/**
- 문제 해석:
갈색 격자수, 노란색 격자 수 yellow 가 매개변수로 주어질 때,
카펫의 가로/세로 크기를 수너대로 담은 배열을 나타내라
- 단, 중앙에는 노란색, 테두리 1줄은 갈색으로 칠해져 있음
- 풀이 방법:
1) 갈색,노란색 격자 수를 더한 값의 약수를 구한다.
2) 그 약수 중에 정답이 있다.
3) (가로-2) * (세로-2) = 노란색의 개수이다.
* 조건 : 가로 길이 >= 세로 길이
**/
static int brown;
static int yellow;
public static void main(String[] args) {
brown = 10;
yellow = 2;
int[] solution = solution();
System.out.println(solution[0] + " " + solution[1]);
}
public static int[] solution() {
int[] answer = new int[2];
int sum = brown + yellow;
ArrayList<String> calNumber = cal(sum);
for (String i : calNumber) {
String[] strArr = i.split(" ");
int x = Integer.parseInt(strArr[0]);
int y = Integer.parseInt(strArr[1]);
if ((x - 2) * (y - 2) == yellow) {
answer[0] = x;
answer[1] = y;
}
}
return answer;
}
public static ArrayList<String> cal(int n) {
ArrayList<String> cal = new ArrayList<>();
for (int i = 0; i <= n; i++) {
for (int j = 0; j <= i; j++) {
if (i * j == n) {
if (i >= j) {
cal.add(i + " " + j);
}
}
}
}
return cal;
}
}
[ 테스트 결과 ]
몇몇 테스트 코드에서 시간 초과가 발생함을 알 수 있습니다.
다른 사람의 코드를 가져와 비교해 보겠습니다.
class Solution {
public int[] solution(int brown, int yellow) {
int[] answer = new int[2];
int sum = brown + yellow;
for (int i = 3; i < sum; i++) {
// 노란 격자가 가운데에 위치하기 위해 세로,가로가 모두 3이상이여야 하므로 3부터 시작
int j = sum / i;
// 가로길이를 바로 합에 나눠줘버려 세로를 구해줌
if (sum % i == 0 && j >= 3) {
// 약수가 되고, j 길이도 3이상인 것을 선택
int col = Math.max(i, j);
int row = Math.min(i, j);
// i,j 중 더 큰 값이 가로 길이가 됨
int center = (col - 2) * (row - 2);
// 가로-2 * 세로-2 = 노란색 격자 수 공식을 사용
if (center == yellow) {
answer[0] = col;
answer[1] = row;
return answer;
}
}
}
return answer;
}
}
경우의 수를 생각해보면 배열의 첫 번째부터 끝까지 더 할 수도 있고, 뺄 수도 있습니다. 그래서 각 원소당 2개의 경우의 수가 발생합니다.
재귀 함수를 사용할 수 있는가에 대해 판단하는 기준은 시간복잡도로 계산하시면 됩니다.
일반적으로 500만 번 이하의 탐색을 하게 되면 재귀함수를 사용할 수 있다고 보고 있습니다.
그러면 최대 20개의 원소를 가진다고 했으므로, 100만 번 정도의 탐색을 하므로 충분히 사용 가능합니다.
2. 재귀로 풀 때 고려사항
재귀로 풀 때 고려해야하는 사항은 크게 두가지가 존재합니다.
- 수행 동작
: 한 번의 동작 안에 어떤 동작을 수행할 것인지를 정의 해야 합니다.
- 언제 탈출 시킬 것인가
: 탈출을 시켜야 재귀 함수가 종료가 되므로 위에 대한 부분도 생각해야합니다.
문제에 대해서는 재귀 함수가 콜 된 인덱스가 배열 길이만큼 되면 탈출 시키면 됩니다.
* 프로그래머스 문제 풀이 팁
: 바뀌지 않을 값들은 멤버 변수로 정의해 사용하는게 편리하다.
[ 소스 코드 ]
public class TargetNumber {
/**
1. 문제
- n개의 음이 아닌 정수들 존재
- 이 정수들을 순서를 바꾸지 않고 적절히 더하거나 빼서 타겟넘버 만들기
- [ 1,1,1,1 ] 로 숫자3 을 만드는 방법을
( -1+1+1+1+1 = 3 )
( +1-1+1+1+1 = 3 ) ...
**/
static int answer = 0;
static int[] numbers;
static int target;
public static void main(String[] args) {
int[] numbers1 = {1, 1, 1, 1, 1};
int[] numbers2 = {4,1,2,1};
solution(numbers1, 3);
System.out.println(answer);
}
public static int solution(int[] _numbers, int _target) {
answer = 0;
numbers = _numbers;
target = _target;
dfs(0,0);
return answer;
}
public static void dfs(int index, int sum) {
// 1. 탈출 방법
if (index == numbers.length) { // 인덱스가 배열 길이가 될 때
if(sum == target){ // 합이 타겟이 될 때
answer++;
return;
}
}
// 2. 구현 동작
try{
// 덧셈을 수행
dfs(index + 1, sum + numbers[index]);
// 뺄셈을 수행
dfs(index + 1, sum - numbers[index]);
} catch (Exception e){
}
}
}
( 단, 앞이 1인 배열은 0번의 위치에 해당됩니다. ex. [ 1,2,3,4 ] , [1,~~~] : 0 [ 2,3,4,1 ] , [2,~~~] : 1... )
그래서 해당하는 위치를 구하려면 k / (n-1)! : 배열의 순서의 번호 k % (n-1)! : 배열 순서 내부 번호
import java.util.ArrayList;
public class skillCheck2 {
/**
- 문제 해석
> 일렬로 줄 서 있음
> 1~n 까지 번호가 매겨져 있음
> n명의 사람이 줄 서는 방법은 여러가지 있음
> 사람의 수 n, 자연수 k가 주어질 때, 사람을 나열하는 방법을 사전순으로 정렬
> k번째 정렬된 수의 배열을 리턴
**/
public static void main(String[] args) {
}
public int[] solution(int n, long k) {
int[] answer = new int[n];
ArrayList<Integer> list = new ArrayList<>();
int fn = 1;
for (int i = 1; i <= n; i++) {
fn *= i; // fac 구하기
list.add(i);
}
k--;
int idx = 0;
while (idx < n) {
fn /= n - idx;
answer[idx++] = list.remove((int) (k / fn));
k %= fn;
}
return answer;
}
}
Arrays.sort(arr, (o1,o2) -> {
if(o1[0] == o2[0]){ // 0번째 요소가 같으면 1번 째 요소로 비교
return Integer.compare(o1[1], o2[1]);
}
else { // 요소 비교
return Integer.compare(o1[0], o2[0]);
}
});
하게 되면 arr { {1,1}, {1,3}, {2,5} } 가 오게 된다.
문자열 배열 비교 방법
Arrays.sort(tickets, new Comparator<String[]>() {
@Override
public int compare(String[] o1, String[] o2) {
return o1[1].compareTo(o2[1]);
}
});
/**
- 문제 이해하기
n개의 노드 그래프
1~n까지의 각 노드
1번 노드에서 가장 멀리 떨어진 노드의 갯수구하기
가장 멀리 떨어진 노드란 최단 경로로 이동했을 때 간선의 개수가 가장 많은 노드
- 해결 과정
* bfs를 활용해 이동 경로 확인
1) 각 노드별 depth를 저장하는 visit를 설정
2) 이를 통해 노드에 depth를 저장
**/
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Queue;
public class FarNode {
private static ArrayList<Integer>[] adj;
private static int[] visit;
private static int depth = 0;
private static int answer = 0;
public static void main(String[] args) {
int n = 6;
int[][] egdes = {{3,6},{4,3},{3,2},{1,3},{1,2},{2,4},{5,2}};
solution(n, egdes);
System.out.println(answer);
}
public static int solution(int n, int[][] edge) {
answer = 0;
visit = new int[n + 1]; // 정점 갯수만큼의 방문 배열 만들기
adj = new ArrayList[n+1]; // 인접리스트 생성
for (int i = 1; i <= n; i++) {
adj[i] = new ArrayList<>();
}
for (int i = 0; i < edge.length; i++) { // 노드 연결
adj[edge[i][0]].add(edge[i][1]);
adj[edge[i][1]].add(edge[i][0]);
}
bfs(1, 1); // 시작 정점을 넣어줌
for (int i = 1; i <= n; i++) { // 그래프 정점이 1부터 시작
if(depth == visit[i]) answer++;
}
return answer;
}
public static void bfs(int start,int count) {
Queue<Integer> q = new LinkedList<>();
q.add(start);
q.add(count);
visit[start] = count;
while (!q.isEmpty()) {
int node = q.poll();
int n = q.poll();
if(depth<n) depth = n; // 가장 깊은 노드를 구함
for (int i = 0; i < adj[node].size(); i++) {
int next = adj[node].get(i); // 다음 정점을 방문함
if(visit[next] != 0) continue; // 연결 간선이 없는 경우
visit[next] = n + 1; // 방문할때마다 카운트 증가
q.add(next); // 다음 방문할 연결된 정점
q.add(n + 1);
}
}
}
}