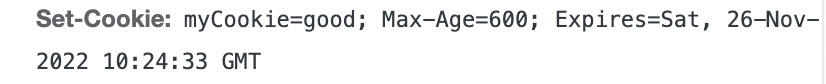스프링은 기본적으로 별다른 설정을 하지 않으면 내부에서 생성하는 빈 오브젝트를 모두 싱글톤으로 생성한다.
싱글톤 패턴
서블릿 클래스당 하나의 오브젝트만 만들어두고,
사용자 요청을 담당하는 여러 스레드에서 하나의 오브젝트를 공유해 동시에 사용한다.
이렇게 애플리케이션 안에 제한된 수의 오브젝트만 만들어서 공유해서 사용하는 것이 싱글톤 패턴의 원리이다.
자바의 싱글톤 패턴을 구현하는 방법
1. 클래스 밖에서 오브젝트를 생성하지 못하게 private로 생성자를 만든다.
2. 생성된 싱글톤 오브젝트를 저장할 수 있는 자신과 같은 타입의 static 필드를 정의한다.
3. 스태틱 팩토리 메소드인 getInstance() 를 만들고, 이 메소드가 최초로 호출되는 시점에서 한번만 오브젝트가 만들어지게 한다.
-> 생성된 오브젝트는 static 필드에 저장된다.
4. 싱글톤 오브젝트가 만들어지고 난 후에는 getInstance 메소드로 이미 만들어진 static 필드에 저장해둔 오브젝트를 넘김
public class Dao {
private static Dao INSTANCE;
private String name;
private Dao(String name){
this.name = name;
}
public static synchronized Dao getInstance(String name){
if(INSTANCE == null) INSTANCE = new Dao(name);
return INSTANCE;
}
}
자바의 싱글톤 패턴의 단점
1) private 생성자를 갖고있어 상속할 수 없다.
2) 만들어지는 방식이 제한적이라 테스트하기 어렵다.
3) 서버환경에서는 여러 JVM에 분산돼서 설치되는 경우에도 각각의 독립된 오브젝트가 생성되 싱글톤 가치가 떨어진다.
4) 전역 상태로 사용되기 쉬워 객체지향에서 권장하지 않는 프로그래밍 방법이다.
싱글톤 레지스트리
하지만 스프링에서는 서버환경에서 싱글톤 방식을 적극 지지한다.
그리고 이를 스프링에서는 싱글톤 형태의 오브젝트를 만들고 관리하는 기능을 제공한다.
스프링 컨테이너는 싱글톤을 생성,관리,공급하는 싱글톤 관리 컨테이너의 역할도 한다.
이 스프링 컨테이너는 위의 static 메소드와 private 생성자 없이도 클래스를 싱글톤으로 활용할 수 있게 해준다.
그래서 관계설정, 컨테이너를 사용한 생성 등에 대한 제어권을 컨테이너에게 넘기는 이유중에 하나도 이 점 때문이다.
예제)
public class UserDao {
private String test;
public UserDao(String test) {
this.test = test;
}
}
@Component
public class DaoFactory {
@Bean
public UserDao userDao() {
return new UserDao("test");
}
}
public class Factory {
public UserDto getUserDto(){
DbConnector connect = new DbConnector();
UserDto user = new UserDto(connect);
return userDto();
}
}
Factory의 getUserDto를 호출하면 디비 커넥션 설정을 가져오고, user 오브젝트를 돌려주는 역할을 해준다.
이를 통해 클라이언트에서는 팩토리 클래스를 활용하면 디비 커넥션, 오브젝트 초기화 부분을 신경쓰지 않고 호출만 하면 된다.
이 팩토리의 역할을 어떻게 정의할 수 있을까?
애플리케이션을 구성하는 핵심적인 로직들의 관계를 정의하는 책임을 맡는 것이다.
즉, 컴포넌트의 구조와 관계를 정의하는 설계도와 같은 역할을 한다고 할 수 있다.
그래서 오브젝트가 어떤 오브젝트를 사용하는지를 정의하는 코드가 주로 들어간다.
제어의 역전이란?
모든 종류의 작업을 사용하는 쪽에서 제어하는 것이 아닌,
오브젝트가 자신이 사용할 오브젝트를 스스로 선택하지 않고 팩토리와 같이 다른 오브젝트에게 모든 제어 권한을 위임하는 것을 의미한다.
예를 들어, 프로젝트의 시작을 담당하는 main 메소드는 엔트리 포인트를 제외하면 모든 오브젝트들에게 제어 권한을 위임한다.
대표적인 기술로 프레임워크가 있다.
프레임워크는 라이브러리들을 활용해 애플리케이션 흐름을 제어하도록 만들어진 반제품이라고 볼 수 있다.
이는 단지, 동작 중에 필요한 작업에 라이브러리를 사용하는 것일 뿐이다.
그리고 개발자는 그 프레임워크가 짜놓은 틀 안에서 애플리케이션 코드를 작성한다.
그러면 개발자는 코드를 작성할 뿐, 실제 애플리케이션을 직접 제어하는 것은 프레임워크가 되는 것이다.
Bean의 등장
팩토리를 이러한 원리를 가지고 스프링에 적용하면 어떻게 될까?
스프링에서는 스프링의 제어권을 가지고 직접 관계를 만들어 부여하는 오브젝트를 Bean 이라고 부른다.
이는 스프링 컨테이너가 생성, 관계 설정, 사용 등을 제어해주는 제어의 역전이 적용된 오브젝트이다.
그리고 이러한 빈의 생성과 관계 설정과 같은 제어를 담당하는 IoC 오브젝트를 빈 팩토리라고 부른다.
빈 팩토리를 활용한 대표적인 오브젝트로 애플리케이션 컨텍스트(ApplicationContext) 가 있다.
Application Context
이 오브젝트는 애플리케이션 전반에 걸쳐 모든 구성 요소의 제어 작업을 담당하는 IoC 엔진이라고 볼 수 있다.
예를 들어,
UserDto 와 DbConnection이 있을 때, UserDto와 DbConnection의 관계 설정을 어떻게 할 지를 제어한다.
하지만 애플리케이션 컨텍스트에서 이 정보를 직접 담고 있진 않다.
대신 설정 정보를 담고 있는 Config 클래스를 불러와서 활용하는 역할을 해준다.
이렇게 그 자체로는 애플리케이션 로직을 담당하고 있진 않지만 IoC 방식을 이용해
애플리케이션 컴포넌트를 생성하고, 사용할 관계를 맺어주는 책임을 담당하는 설계도와 같은 역할을 한다.
* 스프링에서는 이러한 설정 정보를 담당하는 애노테이션을 @Configuration 으로 표시한다.
@Configuration
public class dbConfig {
//
@Bean
public DbConnection connection(){
return new DbConnection();
}
}
public class test(){
//
main(){
ApplicationContext context = new ApplicationContext(DbConfig.class);
}
}
애플리케이션 컨텍스트의 장점
1. 클라이언트는 팩토리의 클래스를 알 필요가 없다.
클라이언트가 오브젝트를 가져올 때마다 팩토리 오브젝트를 생성하는 번거러움을 덜어준다.
그리고 아무리 팩토리가 많아져도 이를 알거나 직접 사용할 필요가 없다.
애플리케이션 컨텍스트가 알아서 가져와 준다.
2. 종합 IoC 서비스를 제공한다.
위와 같은 방식 외에도 오브젝트가 생성되는 방식, 시점, 전략을 다양하게 가져갈 수 있다.
3. 타입만으로 빈을 편리하게 검색할 수 있는 방법을 제공한다.
의존관계 주입
IoC는 스프링에서 아주 폭넓게 사용 되는 용어이다.
단순 서블릿 컨테이너인지, IoC 개념이 적용된 템플릿 메소드 패턴을 의미하는지, IoC 특징을 지닌 기술을 의미하는지 알 수 없다.
그래서 의존 관계 주입(DI) 이라는 명확한 이름을 사용하기 시작했다.
DI는 오브젝트 레퍼런스를 외부로부터 참조받고 이를 통해 다른 오브젝트와 의존관계가 만들어지는 것이 핵심이다.
의존관계
의존 관계란 누가 누구에게 의존하는 관계에 있다는 식이어야 한다. 즉, 방향성이 있다.
즉 "A가 B에 의존하고 있다" 라는 것은 "B가 무언가를 하면 A가 영향을 미친다" 라는 의미이다.
런타임 의존관계
런타임 시에 의존관계를 맺게 되는 특정 오브젝트를 의미한다.
의존 관계 주입의 세가지 조건
1. 클래스나 코드 속에는 런타임 시점의 의존관계가 드러나지 않는다. (인터페이스에만 의존해야 한다)
import spock.lang.Specification
class UpdateBizFleetOrderVinsToPurchasedHandlerTest extends Specification {
}
* 이때, 주의할 점은 클래스를 ctrl + command + T 로 만들 때, 기존에 Test Library JUnit으로 사용하시던 분들은 Groovy로 바꿔줘야 합니다.
4. 라이프 사이클에 맞는 메소드 생성
def setupSpec() {} // 모든 테스트 케이스 실행 전 실행 (@BeforeClass)
def setup() {} // 각 테스트 케이스 실행 전 마다 실행 (@Before)
def cleanup() {} // 각 테스트 케이스 실행 후 마다 실행 (@After)
def cleanupSpec() {} // 모든 테스트 케이스 실행 후 실행 (@AfterClass)
1. openSession(): 마이바티스 설정 파일의 설정을 그대로 사용하는 바이바티스 객체 생성
2. openSession(boolean autoCommit): 마이바티스 설정을 그대로 사용하되 자동 커밋 여부를 변경함
3. openSession(Connection connection) : 마이바티스 연결 정보를 갖는 커넥션 타입 객체를 피라미터로 전달해서 마이바티스 객체 생성 : 만들어진 객체만큼 연결 객체가 갖는 여러 정보를 생성 시점에 설정 가능 : 연결 정보를 직접 사용하기 때문에 "마이바티스와 별도로 트랜잭션 제어 가능"
2번의 경우,association 태그 내에서 resultMap에 지정한 형태로 결과 값을 담게 된다.
도메인 관계
[User] 1:1 [Board] [Apply] N:1 [Board]
@Data public class User { private Long id; pirvate String name; }
@Data public class Board { private Long id; private String name; private User user; // has one relation ( association ) private List<Apply> apply; // has many relation ( collection ) }
public class Apply { private Long id; private Board board; // has one relation ( association ) private User user; // has one relation ( association ) }
mybatis:
config: mybatis-config.xml // config 위치 : static 바로 아래
type-aliases-package: kia.com.mybatistest.model // dao,dto가 위치한 곳
mapper-locations: mybatis/mapper/*.xml // mapper를 위한 xml 파일이 위치한 곳 ( static 아래가 아닌 resources 아래 )
### Mapper interface 작성
@Repository
@Mapper
public interface UserMapper {
List<UserDto> getAllUserDataList();
}
public interface UserServiceInterface {
public List<UserDto> getAllUserDataList();
}
### Service implement 작성
@Service
@RequiredArgsConstructor
public class UserService implements UserServiceInterface {
private final UserMapper userMapper;
@Override
public List<UserDto> getAllUserDataList() {
return userMapper.getAllUserDataList();
}
}
### Test Controller 구성
@RequiredArgsConstructor
@RestController
public class MemberTestController {
private final UserService userService;
@GetMapping("/user/test")
public List<UserDto> getAllDataList() {
return userService.getAllUserDataList();
}
}
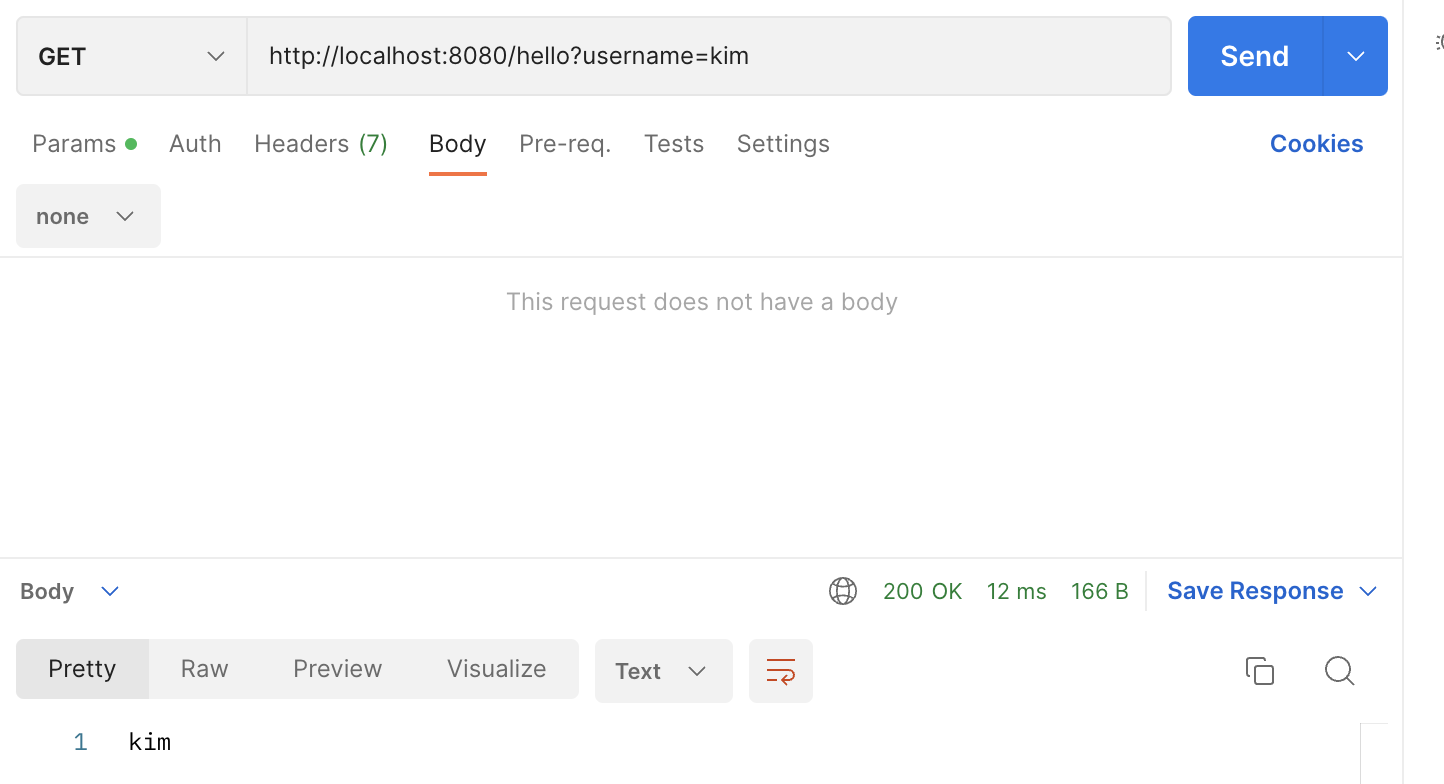
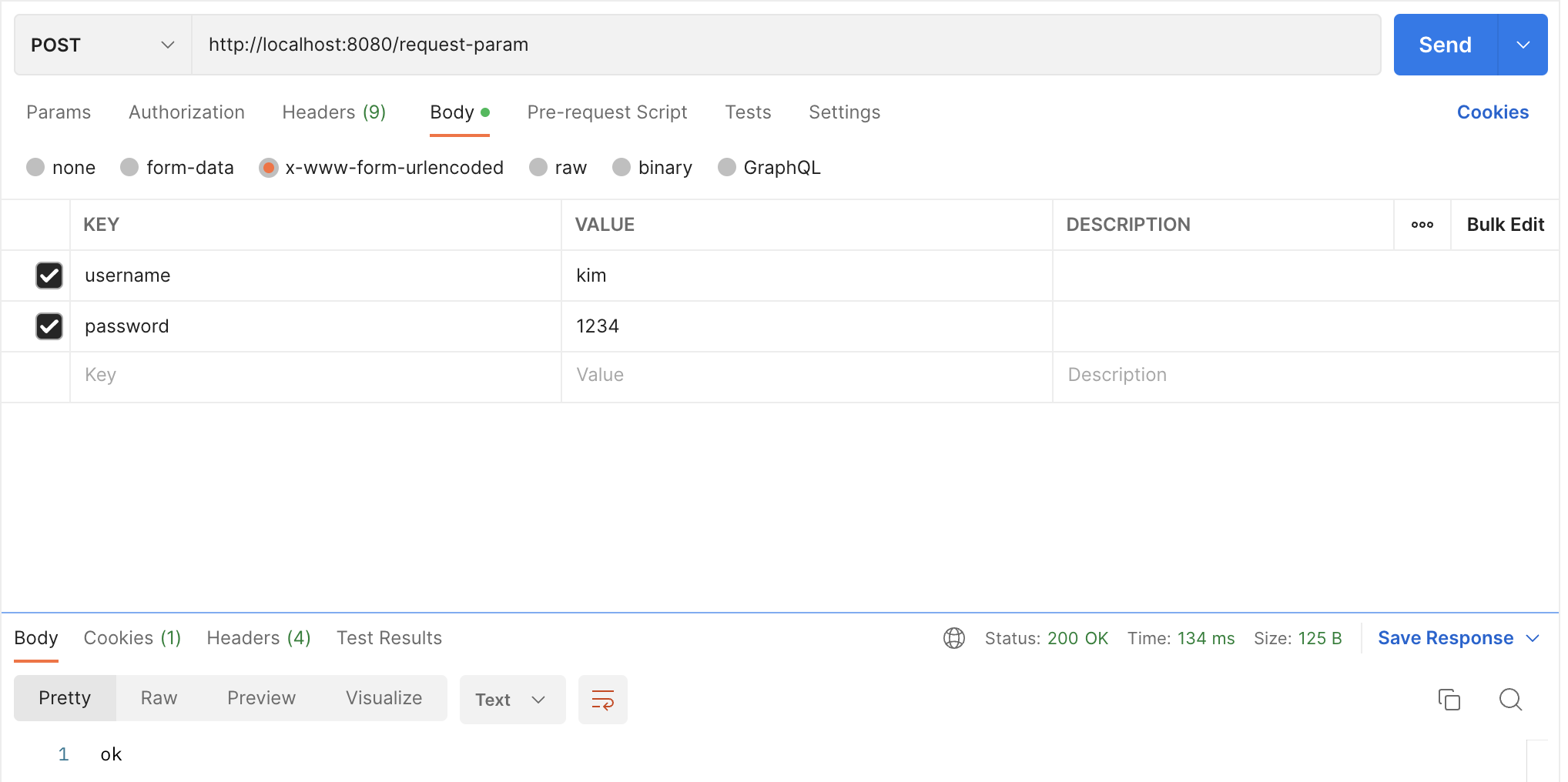
위의 service 코드를 controller에 @RequestParam 을 통해 간단하게 나타낼 수 있습니다.
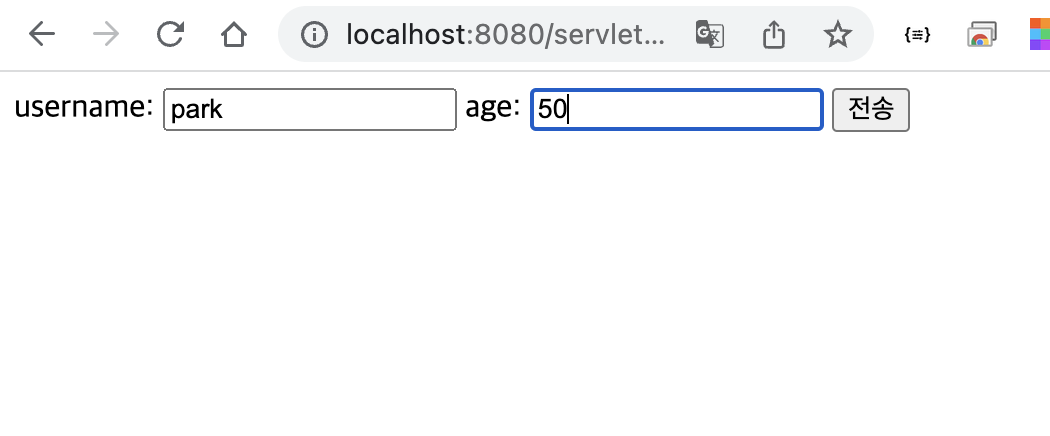
@PostMapping("/save")
public String process(
@RequestParam String username,
@RequestParam String password,
Model model
) {
Member member = new Member(username, password);
memberRepository.save(member);
model.addAttribute("member", member);
return "save-result";
}
1) 비연결성 : HTTP는 인터넷상에서 불특정 다수의 통신 환경을 기반으로 설계되었습니다. 만약, 서버에서 다수의 클라이언트와 계속 연결을 유지한다면 많은 리소스가 발생합니다. 그래서 서버가 한 번 연결을 맺은 후, 클라이언트 요청에 대해 서버가 응답을 마치면 맺었던 연결을 끊어버리는 성질을 가지게 되는데 이를 비연결성이라고 부릅니다. 하지만 이러한 비연결성은 모든 요청에 대해 매번 새로운 연결을 시도하므로 연결/해제에 대한 오버헤드를 가집니다.
2) 무상태 서버가 클라이언트의 상태를 보존하지 않음으로 클라이언트의 상태를 알 수 없는 상태입니다.
이러한 무상태는 로그인이 필요없는 단순한 서비스 소개 화면 정도의 구현에는 유용합니다.
하지만 사용자가 로그인한 상태를 서버에 유지 시켜 줘야 하는 경우 무상태로는 설계를 할 수 없게 됩니다.
이를 위해 세션과 쿠키를 조합하여 상태를 유지합니다.
Cookie
클라이언트 로컬에 저장되는 키와 값이 들어있는 작은 데이터 파일
사용자 인증이 유효한 시간을 명시할 수 있음
유효 시간이 정해지면 브라우저가 종료되어도 인증이 유지됨
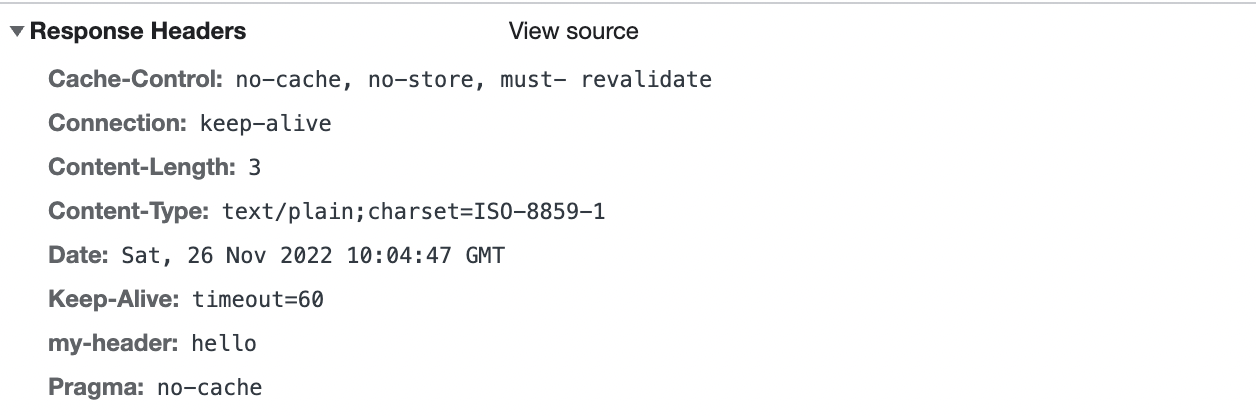
Response Header 에 Set-Cookie 속성을 사용해 클라이언트에 쿠키를 만들 수 있음
Cookie 구성요소
이름 : 쿠키를 구별하는데 사용되는 이름
값 : 쿠키의 이름과 관련된 값
유효시간 : 쿠키 유지시간
도메인 : 쿠키를 전송할 도메인
경로 : 쿠키를 전송할 요청 경로
Cookie 동작방식
클라이언트가 페이지를 요청
서버에서 쿠키 생성
HTTP 헤더에 쿠키를 포함시켜 응답
브라우저가 종료되어도 쿠키 만료 시간이 있다면 클라이언트에서 보관함
같은 요청을 할 경우 HTTP 헤더에 쿠키를 함께 보냄
서버에서 쿠키를 읽어 이전 상태 변경할 필요가 있을 때 쿠키를 업데이트
Cookie 사용 예시
방문 사이트에서 "아이디,비번 저장하시겠습니까?"
쇼핑몰 장바구니 기능
자동로그인, 팝업에서 "오늘 더 이상 이 창 보지 않음" 체크
Session
브라우저와 웹 서버가 연결되어 브라우저가 종료될때까지의 시점
세션은 쿠키를 기반으로 하지만, 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 서버 측에서 관리
서버는 클라이언트 구분을 위해 세션 ID를 부여하며, 웹 브라우저가 서버에 접속해 브라우저를 종료할 때가지 인증상태 유지
접속 시간에 제한을 두어 일정 시간 응답 없을 경우 유지되지 않게 설정 가능
사용자에 대한 정보를 서버에 두기 때문에 쿠키보다 보안에 좋음
하지만 사용자가 많아질수록 서버 메모리를 많이 차지함
즉, 동접자 수가 많은 경우 웹 서버에 과부하를 주게 됨
Session 동작 방식
1. 클라이언트가 브라우저를 통해 서버에 접속한다.
2. 서버는 세션id를 쿠키에 담아 되돌려준다.
3. 클라이언트는 세션id를 담은 쿠키인 세션 쿠키를 이후 요청부터 계속해서 전달한다.
이를 세션 기반 인증 방식이라고 하며, 간단하게 세션이라고 부른다.
Session 사용 예시
로그인 같이 보안상 중요한 작업 수행할 때 사용
JWT
JSON 객체를 사용해서 토큰 자체에 정보들을 저장하고 있는 Web Token
세션은 사용자 수 만큼 서버 메모리를 차지하기 때문에, 최근에는 이러한 토큰 기반 인증 방식을 사용한다.
JWT 구성
- Header
Signature 를 해싱하기 위한 알고리즘 정보들이 담겨져 있음
- Payload
서버와 클라이언트가 주고받는, 시스템에서 실제로 사용될 정보에 대한 내용을 담고 있습니다.
여기에 담는 정보의 "한 조각" 을 클레임이라고 부릅니다. 이 클레임은 토큰에 여러개가 들어갈 수 있습니다.